使用java爬取百度贴吧李毅吧的全部帖子
爬取的网站
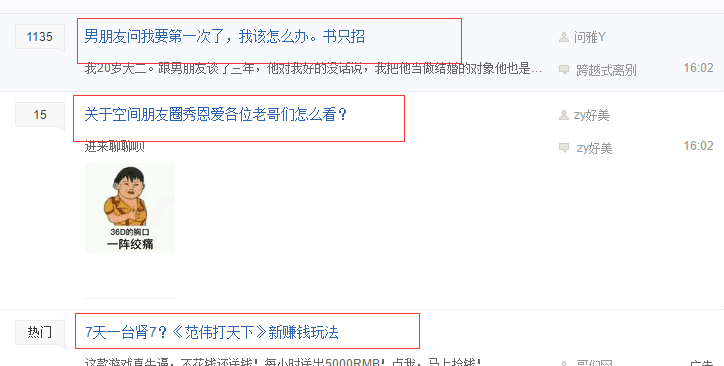
百度李毅贴吧所有的帖子名称
获取网页
使用Jsoup包下的方法Jsoup.connect(url).get()返回的是一个Document类型
url就是李毅吧的首页网址
String url = "http://tieba.baidu.com/f?kw=%E6%9D%8E%E6%AF%85&ie=utf-8&pn=0";
Document doc = Jsoup.connect(url).get();
1正则表达式匹配
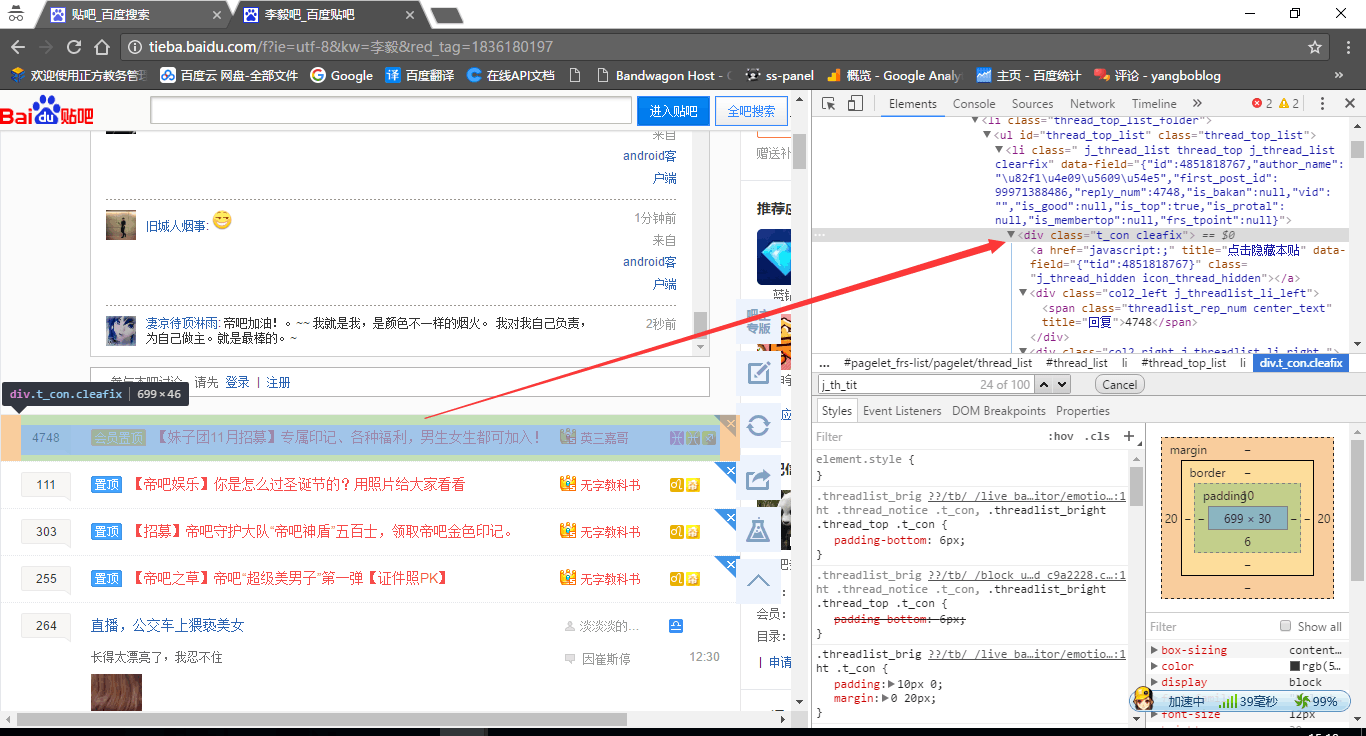
主方法,使用正则匹配出需要的内容.
需要的内容
代码(这里只爬取了贴吧前100页的帖子)
package com.yb.crawler.test;
import com.yb.crawler.utils.JsoupUtils;
import com.yb.crawler.utils.RegexStringUtils;
import java.util.List;
/**
* Created by 杨波 on 2016/12/24.
*/
public class Demo {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
String url = "http://tieba.baidu.com/f?kw=%E6%9D%8E%E6%AF%85&ie=utf-8&pn="+i*50;
//获取页面为String类型
String html = JsoupUtils.html(url);
// System.out.println(html);
//正则表达式
String regex = "a href=\".+?\" title=\"(.+?)\" target=\"_blank\"";
//匹配正则表达式
List<String> lists = RegexStringUtils.regexString(html, regex);
for (String str : lists) {
System.out.println(str);
}
}
}
}
package com.yb.crawler.utils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
/**
* Created by 杨波 on 2016/12/25.
*/
public class JsoupUtils {
public static String html(String url){
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
return doc.toString();
}
}
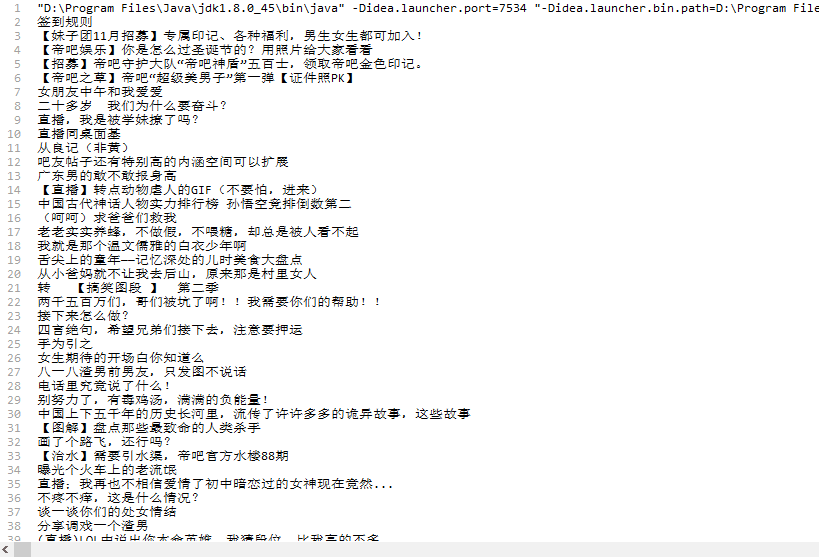
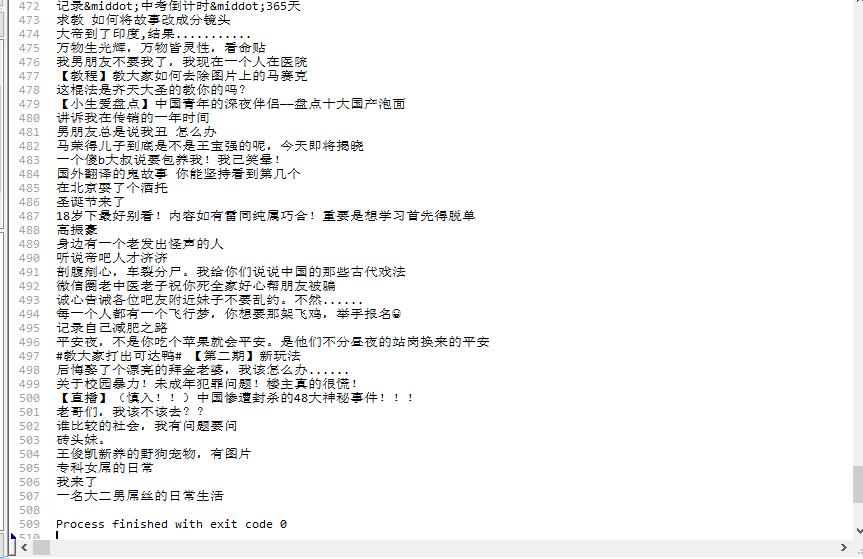
1匹配结果
2Jsoup自带的方法匹配
这里使用 Document对象的方法类似与javascript
匹配出帖子标题,作者,回复量,发帖时间。
代码
package com.yb.crawler.test;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* Created by 杨波 on 2016/12/24.
*/
public class JsoupTest {
public static void main(String[] args) {
for (int j = 0; j < 100; j++) {
Document doc = null;
Elements divs = null;
//回复
List<String> reps = new ArrayList<String>();
//帖子主题
List<String> titles = new ArrayList<String>();
//作者
List<String> authers = new ArrayList<String>();
//发帖时间
List<String> times = new ArrayList<String>();
String url = "http://tieba.baidu.com/f?kw=%E6%9D%8E%E6%AF%85&ie=utf-8&pn="+j*50;
//List<String> list =new ArrayList<String>();
try {
//找到当前页面的所有满足条件的div
divs = Jsoup.connect(url).get().getElementsByAttributeValue("class", "t_con cleafix");
//遍历
for (Element div : divs) {
String title = div.select(".j_th_tit").attr("title");
titles.add(title);
String rep = div.getElementsByAttributeValue("class", "threadlist_rep_num center_text").text();
reps.add(rep);
String auther = div.select(".tb_icon_author span").text();
authers.add(auther);
String time = div.select("span.is_show_create_time").text();
times.add(time);
}
} catch (IOException e) {
e.printStackTrace();
}
for (int i = 0; i < divs.size(); i++) {
System.out.println("帖子标题:" + titles.get(i));
System.out.println("作者:" + authers.get(i));
System.out.println("回复量:" + reps.get(i));
System.out.println("创建时间:" + times.get(i));
System.out.println();
}
}
}
}
2匹配结果

